I was a Software Engineer at Baidu Apollo, where I contributed to the development of the Apollo Navigation Pilot (ANP), i.e. Baidu's Full Self-Driving (FSD),
which has been successfully deployed on Jiyue-01 cars and delivered to customers by the end of 2023.
Before focusing on self-driving cars, I was a Researcher and Engineer at Robotics and Auto-driving Lab (RAL), Baidu Research, under the mentorship of
Prof. Ruigang Yang and
Prof. Dinesh Manocha
where I specialized in the design and development of
Autonomous Excavator Systems.
Prior to that, I was a Research Assistant
collaborating with Prof. Jia Pan on research projects in robotic navigation and multi-robot collision avoidance.
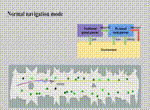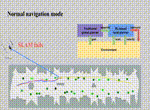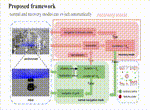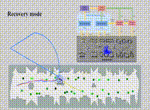
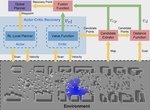
We present an autonomous excavator system (AES) for material loading tasks.
Our system can handle different environments and uses an architecture that combines perception and planning.
AES has been deployed for real-world operations for long periods and can operate robustly in challenging scenarios.
We present a novel optimization-based framework for autonomous excavator trajectory generation under various objectives,
including minimum joint displacement and minimum time.
We present a decentralized sensor-level collision avoidance policy for multi-robot systems.
The learned policy is also integrated into a hybrid control framework to further improve the policy's robustness and effectiveness.
Our learned policy enables a robot to make effective progress in a crowd without getting stuck.
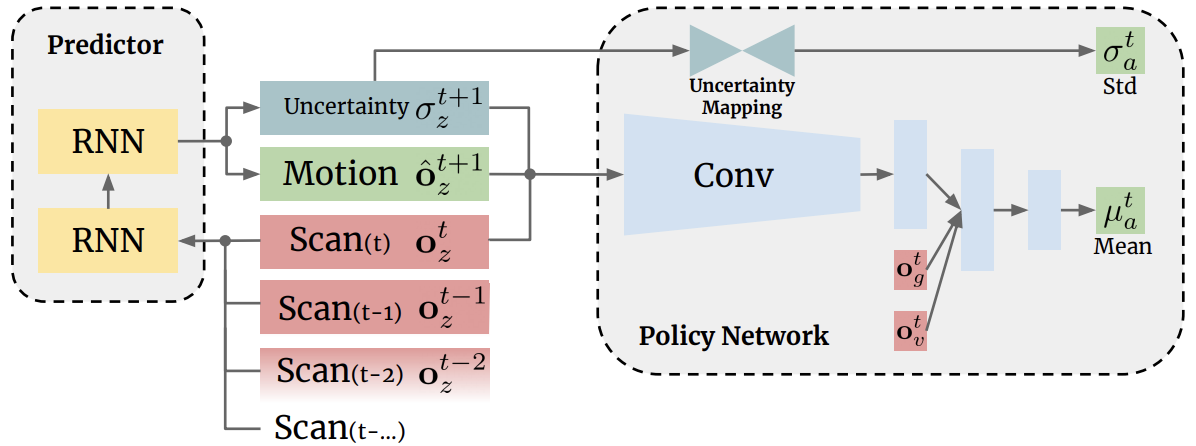
We present a novel approach for uncertainty-aware navigation by introducing an uncertaintyaware predictor to model the environmental uncertainty, and
propose a novel uncertainty-aware navigation network to learn resilient behaviors in the prior unknown environments
We aim to enable a mobile robot to navigate through environments with dense crowds,
e.g., shopping malls, canteens, train stations, or airport terminals.
Here we propose a navigation framework that handles the robot freezing and the navigation lost
problems simultaneously.
As a first step toward reducing the performance gap between decentralized and centralized multi-robot collsion avoidance,
we present a multi-scenario multi-stage training framework to
find an optimal policy which is trained over a large number
of robots on rich, complex environments simultaneously using
a policy gradient based reinforcement algorithm.
This paper is our first step toward learning a reactive
collision avoidance policy for multi-agent collision avoidance. By carefully designing the data collection process
and leveraging an end-to-end learning framework, our method
can learn a deep neural network based collision avoidance
policy which demonstrates an advantage over the state-of-theart ORCA policy in terms of ease of use,
success rate, and navigation performance.
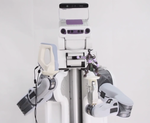
We present our pick-and-place system in detail while highlighting
our design principles for the warehouse settings, including
the perception method that leverages knowledge about its
workspace, three grippers designed to handle a large variety of
different objects in terms of shape, weight and material, and
grasp planning in cluttered scenarios.
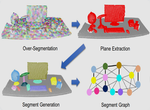
We propose a data-driven approach to modeling contextual information
covering both intra-object part relations and inter-object object layouts.
Our method combines the detection of individual objects and object groups within the same framework,
enabling contextual analysis without knowing the objects in the scene a priori.
We present an intrusive acquisition approach for acquiring and modeling of plants and foliage,
which disassembles the plant into disjoint parts that can be accurately scanned and reconstructed offline.
We propose autonomous scene scanning by a robot to relieve humans from such a tedious task.
The presented algorithm interleaves between scene analysis for extracting objects and robot conducted validation for
improving the segmentation and object-aware reconstruction.
We propose a quality-driven, Poisson-guided autonomous scanning method to ensure the high quality scanning of the model.
This goal is achieved by placing the scanner at strategically selected Next-Best-Views (NBVs) to ensure progressively capturing the
geometric details of the object, until both completeness and high fidelity are reached.
We designed several quadruped robots from scratch and implemented discrete reaching movement
and rhythmic movements (four different gaits) on these robots using Central Pattern Generator based
locomotion control methods.
Speech Controlled Mobile Robot
Pinxin Long, Ke Zhao, Jian Zheng. 2010
We created a robot using STM32 and LD3320 chips running Chinese Speech Recognition application.
This application enables the robot to perform various movement (e.g. move forward, turn left, stop, etc.)
based upon user interaction by speech.
 hide forever |
hide once
hide forever |
hide once